


let http = require('http')
let https = require('https')
let url = require('url') // 用于解析url地址
let cheerio = require('cheerio') // 引入第三方包
const app = http.createServer((req, res) => {
let urlobj = url.parse(req.url, true) // 转换为对象
// console.log(urlobj);
res.writeHead(200, {
"Content-Type": "application/json;charset=utf-8",
"access-control-allow-origin": "*" // 允许所有域通过控制
})
switch (urlobj.pathname) {
case '/api/user':
httpsGit((data)=>res.end(spider(data)))
break
default:
res.end('404')
break
}
})
app.listen(8080, () => {
console.log('localhost:8080')
})
function httpsGit (response) {
let list = ''
https.get('https://i.maoyan.com/#movie',(res)=>{
res.on("data",(data)=>{
list+=data
}) // 有数据返回就会触发,数据流的方式一点一点的返回
res.on('end',()=>{ // 数据合并到一起后,end可以拿到完整数据
response(list)
})
})
}
function spider(data) {
// 需要下载第三方模块解析 : cheerio pnpm add cheerio
const $ = cheerio.load(data)
let $movie = $(".mb-outline-b.content-wrapper .title.line-ellipsis ") // 选择标签转换为对象结构
let arr = []
$movie.each((index,value)=>{
arr.push($(value).text()) // 转换成jq对象 查找.nav-item-span : find('.nav-item-span')
})
return JSON.stringify(arr)
}同ip访问次数过多可能被封ip地址导致访问不了,换个网就可以了
效果截图:
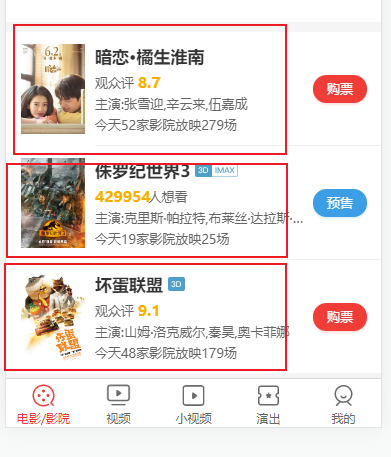



请登录后查看回复内容